DDN 正在获得 英伟达 的认证,以提供参考架构的存储组件,云服务提供商 (CSP) 将使用该组件来构建 英伟达 GPU 驱动的 AI 工厂基础设施。
此 CSP 参考架构 (RA) 是用于构建数据中心的蓝图,这些数据中心可以提供类似于三大公有云和超大规模云的生成式 AI 和大型语言模型 (LLM) 服务。英伟达 云合作伙伴计划涵盖以云或托管服务模式向使用 英伟达 产品的客户提供托管软件和硬件服务的组织。
DDN的高级副总裁兼首席营销官Jyothi Swaroop在一份声明中表示:“这种参考架构是与英伟达合作开发的,为云服务提供商提供了与全球最大的AI数据中心(包括英伟达的Selene和Eos超级计算机)中已经投入生产的AI系统的可扩展AI系统的相同蓝图。
借助这种经过充分验证的架构,云服务提供商可以确保其端到端基础设施针对高性能 AI 工作负载进行优化,并可以使用可持续且可扩展的构建块快速部署,这不仅可以节省大量成本,而且可以大大缩短上市时间。
英伟达 解决方案架构和工程副总裁 Marc Hamilton 在博客中写道:“LLM 训练涉及许多 GPU 服务器协同工作,它们之间以及与存储系统之间不断通信。这意味着数据中心的东西向和南北向流量,这需要高性能网络来实现快速高效的通信。
英伟达的云合作伙伴 RA 包括:
来自 英伟达 及其制造合作伙伴(包括 Hopper 和 Blackwell)的 英伟达 GPU 服务器。
来自认证合作伙伴的存储产品,包括经过 DGX SuperPOD 和 DGX Cloud 验证的存储产品。
Quantum-2 InfiniBand 和 Spectrum-X 以太网东西向网络。
BlueField-3 DPU,用于南北向网络和存储加速、弹性 GPU 计算和零信任安全。
用于配置、监控和管理 AI 数据中心基础设施的带内/带外管理工具和服务。
英伟达 AI Enterprise 软件,包括:
Base Command Manager Essentials,可帮助云提供商配置和管理其服务器。
NeMo 框架,用于训练和微调生成式 AI 模型。
NIM 微服务,旨在加速生成式 AI 在企业中的部署。
Riva,用于语音服务。
RAPIDS 加速器,用于加速 Spark 工作负载。
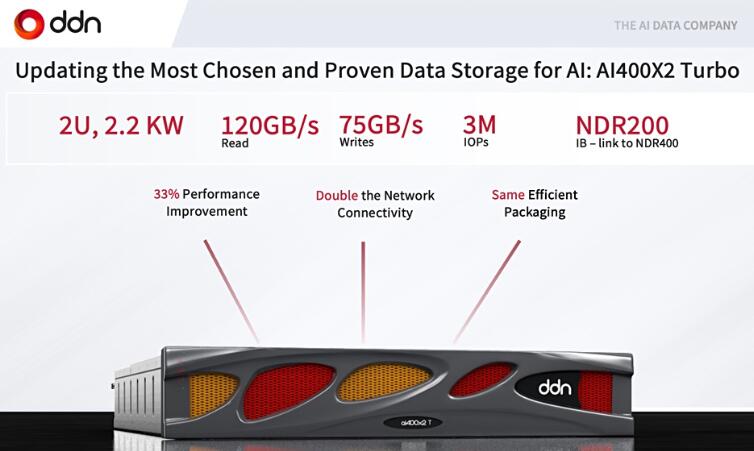
DDN 存储组件使用其基于 Lustre 的 A³I(加速、任意规模 AI)系统,该系统基于 AI400X2T 全闪存 Turbo 设备和 DDN 的 Insight 管理器。DDN 表示,这是一款经过全面验证和优化的 AI 高性能存储系统,适用于 CSP,采用 英伟达 的 HGX H100 8-GPU 服务器服务。
每个 AI400X2T 设备直接向 HGX H100 系统提供超过 110 GBps 和 300 万 IOPS。
A³I 多轨功能支持在 HGX 系统上对多个网络接口进行分组,从而实现更快的聚合数据传输能力,而无需任何交换机配置,例如通道组或绑定。它可以动态平衡所有接口之间的流量,并主动监控链路运行状况,以便快速检测故障并自动恢复。
热节点软件增强功能允许将 HGX 系统中的 NVMe 驱动器用作只读操作的本地缓存。它提高了在工作流期间多次访问数据集的应用程序的性能。这在深度学习 (DL) 训练中很常见,在深度学习 (DL) 训练中,相同的输入数据集或同一输入数据集的部分在多次训练迭代中被重复访问。
A³I 具有共享的并行架构,具有冗余和自动故障转移功能,并为在 HGX 系统上运行的所有规模的 DL 工作流启用和加速端到端数据管道。DDN 表示,通过同时在多个 HGX 系统上执行 AI 应用程序并参与候选神经网络变体的并行训练工作,可以实现显着的加速。
DDN RA 指定“对于 NCP(英伟达 云合作伙伴)部署,DDN 使用两种不同的设备配置来部署共享数据平台。AI400X2T-OSS 设备通过四个 OSS(对象存储服务器)和八个 OST(对象存储目标)设备提供数据存储,并提供 120、250 和 500 TB 的可用容量选项。AI400X2-MDS 设备通过四个 MDS(元数据服务器)和四个 MDT(元数据目标)设备提供元数据存储。每个设备提供 92 亿个 inode。这两种设备配置必须联合使用以提供文件系统,并且必须使用 ConnectX-7 HCA 通过融合以太网 RDMA (RoCE) 连接到 HGX H100 系统。每个设备都提供 8 个接口,每个 OSS/MDS 两个接口,用于连接到存储结构。
RA 包含用于将 DDN 存储连接到 127、255、1,023 和 2,047 个 HGX H100 系统的配置图;无论以何种标准衡量,这都是大型钢铁基础设施。
DDN 表示,单个AI400X2T为单个 HGX H100 GPU 服务器提供 47 GBps 的读取带宽和 43 GBps 的写入带宽。昨天,我们注意到 Western Digital 的 OpenFlex Data24 全闪存分解 NVMe 驱动器存储使用 GPUDirect 为 GPU 服务器提供据称的 54.56 GBps 读取和 52.6 GBps 写入带宽。但是,WD 不是 英伟达 Cloud 合作伙伴。
我们最近介绍了 MinIO 的 DataPOD,它将存储的对象交付到 GPU 服务器,“通过分布式 MinIO 设置,在八节点集群中提供 46.54 GBps 的平均读取吞吐量 (GET) 和 34.4 GBps 的写入吞吐量 (PUT)。一个 32 节点的集群提供了 349 GBps 的读取吞吐量和 177.6 GBps 的写入吞吐量。您可以纵向扩展集群大小以达到所需的带宽级别。与 WD 一样,MinIO 不是 英伟达 Cloud 合作伙伴。
DDN 表示,其云参考架构通过确保其 GPU 的最大性能、缩短部署时间和处理未来扩展需求的指导方针来满足服务提供商的需求。在此处查看 DDN 的 CSP RA。








