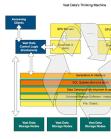
所有闪存阵列供应商VAST Data已将其存储控制器软件移植到英伟达的BlueField-3 GPU中,将其存储的数据输入英伟达GPU服务器的核心,并将其转换为AI数据引擎。
BlueField-3是一个具有集成软件定义的硬件加速器的网络平台,用于网络、存储和安全。英伟达的BlueField-3产品组合包括DPU和SuperNIC,通过ROCE提供RDMA,两者均以高达400Gbps的速度运行,并具有PCIe第5代接口。VAST Data提供了一个分解的单QLC闪存层、并行、扩展、基于文件的存储系统,并在此基础上构建了多层软件:数据目录、全局命名空间、数据库和即将到来的数据引擎,所有这些都以人工智能为重点。
VAST Data联合创始人Jeff Denworth在一份声明中谈到了人工智能工厂架构的消息,他说:“这个新架构是表达VAST数据平台并行性的完美展示。有了NVIDIA BlueField-3 GPU,我们现在可以充分实现我们自公司成立以来一直致力于实现的分类数据中心愿景的潜力。”
现有的VAST存储控制器节点(C节点)是x86服务器。控制器软件已移植到BlueField-3卡上的16个Armv8.2+A78 Hercules核心,这种新的VAST架构正在GPU-as-a-service云场供应商CoreWeave进行测试和部署。
VAST强调了其采用BlueField-3(BF3)控制器的四个方面:
更少的独立计算和网络资源,与使用以前的VAST分布式数据服务基础设施部署NVIDIA供电的超级计算机(GPU服务器)相比,VAST基础设施的功耗和数据中心占地面积减少了70%,净能耗节省了5%以上。
通过为每个GPU服务器提供一个专用的并行存储和数据库容器,消除对数据服务基础设施的争用。每个BlueField-3都可以读取和写入VAST数据系统的共享命名空间,而无需跨容器协调IO。
增强了安全性,因为数据和数据管理仍然受到保护,并与主机操作系统隔离。
以本机方式向主机操作系统提供块存储服务—与VAST的文件、对象和数据库服务相结合。
第四点是BlueField-3 SNAP功能,通过NVMe和VirtIO blk提供弹性块存储。VAST Data的AI/HPC解决方案工程总监Neeloy Bhattacharyya告诉我们,这不是VAST的唯一功能:“它位于任何包含BF3的GPU服务器上,没有操作系统限制或BF3连接的平台限制。块设备是从BF3提供的,因此它可以用于使GPU服务器无状态。”
我们询问VAST现在是否通常向主机系统提供块存储服务?巴塔查里亚回答说:“还没有,这将在今年晚些时候推出。”
VAST有带有BF1的Ceres存储节点(D节点),我们询问块协议是否会包括它们:“是的,块设备出现在BF3上,所以CNode功能在后端与之交谈的硬件无关紧要。”
我们还询问,这是否有效地更新了2022年3月Ceres BlueField 1的原始公告。他说:“不,这个公告是在基于GPU的服务器中托管的BF3上运行的逻辑功能(也称为CNode)。这意味着VAST现在有一个端到端的BlueField解决方案(在GPU服务器中的BF3和DBox中的当前BF1之间)。通过在BF3上托管CNode,每个GPU服务器都有专门的资源来访问存储,这提供了安全性,消除了GPU服务器之间的争用,并简化了扩展。”
早在去年5月,我们就用图表(见上图)解释了VAST的思维机器的愿景,巴塔查里亚告诉我们:“这就是愿景的实现。”
CoreWeave工程副总裁Peter Salanki表示:“VAST革命性的架构改变了CoreWeaver的游戏规则,使我们能够完全分解我们的数据中心。我们正在将VAST的高级软件直接无缝集成到我们的GPU集群中。”
表演角度很有趣。由于VAST侧的数据路径中不涉及x86服务器,因此不需要x86服务器主机CPU绕过GPUDirect。Denworth告诉B&F:“就性能而言,在BlueField处理器上引入VAST的软件不会改变我们的DBox数量,这些数量是正交的。我们目前从主机中运行的BlueField-3中获得6.5 GBps的带宽。聚合才是最重要的……一些主机有一个BF-3,另一些主机有两个用于此目的的BF-3,这导致每个主机最多13 GBps。大型集群有1000台带有GPU的机器m.因此,我们主要讨论的是能够为每1000个客户提供高达13 TB的数据。”
Supermicro和EBox
VAST Data还与Supermicro合作,为服务提供商、超大规模科技公司和以数据为中心的大型企业提供经英伟达认证的全栈、超大规模端到端人工智能系统。客户现在可以直接从Supermicro或选择分销渠道购买建立在行业标准服务器上的完全优化的VAST数据平台AI系统堆栈。
作为其中的一部分,伟速达员工、全球业务发展副总裁John Mao在LinkedIn上发布的一篇帖子称,该公司已经开发了一种“EBox”,即一个标准(非HA)服务器节点有资格将伟速达的“CNode”软件容器和伟速达“DNode”容器作为微服务安装在同一台机器上。
“虽然从物理外观来看,此产品可能与市场上许多其他软件定义的存储解决方案类似,但重要的是要了解DASE软件体系结构保持100%完整,以保持真正的集群范围的数据和性能并行性(即,不需要分布式锁或缓存管理,每个CNode容器仍然安装每个SSD以显示为本地磁盘,并且CNode容器从不在读/写数据路径中相互通信。)”
写入速度增加
Denworth写了一篇博客“We’ve Got The Write Stuff…Baby”,讲述了随着人工智能训练处理规模的不断扩大意味着在工作中更需要每隔一段时间进行检查点检查,VAST提高其系统的写入速度。其想法是,如果基础设施组件出现故障,它将防止重新运行整个作业。我们在博客上线前看到了它的副本,Denworth说:“大型人工智能超级计算机正在开始改变读/写I/O的平衡,我们VAST希望随着这些演变而发展。今天,我们宣布了两项新的软件进步,这将有助于使每个VAST集群更快地进行写密集型操作。”
它们是SCM RAID和溢出。关于存储类内存(SCM)RAID,Denworth写道:“到目前为止,对VAST系统的所有写入都已镜像到存储类内存设备(SCM)中。镜像数据不如使用擦除代码更高效……从5.1开始(2024年4月提供),我们很自豪地宣布,当数据流入系统的写入缓冲区时,RAID将加速写入路径。此简单的软件更新将带来50性能的性能提升。”
目前,VAST系统中的写缓冲区是具有固定容量的SCM驱动器,其容量可能小于检查点AI作业所需的容量。因此:“今年夏天晚些时候(2024年),VAST OS的5.2版将支持一种新模式,在这种模式下,大型检查点写入将溢出,也可以直接写入QLC闪存。这种方法可以智能地检测系统何时频繁写入,并允许大型瞬态写入溢出到QLC闪存中。”
总之,这两个变化将有助于减少人工智能训练所需的VAST硬件:“当考虑如何为大型人工智能计算机配置这些系统时,写入密集型配置将在6个月内将所需硬件减少62%……如果我们将NVIDIA DGX SuperPOD的性能大小作为基准,我们的写入流优化将大大减少单个可扩展单元(SU)所需的硬件数量。”